Circuit Breakers and Microservices


Making microservices resilient and self-healing
A microservice is not a monolith
Bad Version Resilience
Netflix's Hystrix example
Velocity needs resilience
From breaker to broker
Kevin Marks / November 3, 2016
Making microservices resilient and self-healing
A worry that people have when moving to microservices from a monolithic application is that there are more moving parts where something can go wrong; that a problem with any of the services will take everything down.
This is a concern, but to assume it only applies to microservices is to miss one of their key advantages: each service has independent status. A bug in a monolith will likely take everything down, or require lots of local custom error handling and state management. With microservices, the common RPC boundary between services means that we can use Circuit Breakers to protect the system as a whole from problems in its component services.
An analogy here is the difference between using a file-based protocol and a network one like TCP—the file system seems simpler, but the network protocol has much more resilience built in. It can cope with lots of different components coming and going, while still delivering a stream of bytes to the caller.
The Circuit Breaker pattern is usually described in terms of network coupling. To protect the system against transient failures of subcomponent services, Circuit Breakers decouple those that are suffering delays or timeouts to prevent cascade failures. The assumption is that the service call itself is what is being protected against – Martin Fowler’s clear explanation of the pattern takes this as the assumed benefit.
Similarly, Microsoft’s discussion of circuit breakers says, ‘These faults can range in severity from a partial loss of connectivity to the complete failure of a service.’
A microservice is not a monolith
While this makes the case for circuit breakers in general, there is an implicit assumption here that each microservice is a monolith that works or fails as a whole – that it doesn’t have multiple available instances to choose between. This will likely be true initially, or in small systems, but as the system grows adding redundant instances makes more sense.
By rebuilding an application as a network of microservices, each single point of failure is naturally easier to make resilient against machine or network failure by adding redundancy. Each service can have multiple instances running, and calls to them can be distributed between running versions. A key motivation for switching to microservices in the first place is to provide such runtime resilience.
Thus the circuit breaker should not really apply to the service as a whole, but to individual instances of the service. It should inform the choices made by the routing layer of which instance to send a request to. This could also avoid the problem we see when applying random or round-robin routing to services where the response time has a very asymmetric time distribution. By communicating detailed available information into the routing layer, problems like the Heroku Ruby routing failure could be mitigated.
However, the other key goal is to be able to update parts of the system independently – to replace a focused microservice without changing all the code that touches it too.
With a monolith, upgrading happens in lockstep, with all the dependencies tightly coupled. Microservices are more decoupled — there is an RPC API boundary between services, and the Circuit Breaker will wrap this and catch timeout or queuing failures. It will act as a backstop to round-robin or despatch queues that are suffering from one slow or failing instance, isolating it and alerting operations that something needs to be fixed, while keeping the overall system running.
In this respect, the ‘circuit breaker’ analogy doesn’t quite fit – it is more like a Uninterruptible Power Supply where alternative power sources take over when there is a failure.
Just as the resilience of networking protocols can mask connectivity problems by automatically retransmitting, circuit breakers can hide error states if they aren’t monitored as well.
Bad Version Resilience
Testing a new version of a microservice for interoperability bugs is very challenging. When a new version is rolled out, multiple microservices that depend on the original service are affected. With each dependent microservice on its own release cycle, freezing releases for a complete integration test cycle is frequently not practical.
Thus, in a microservices architecture, a gradual migration to the new version of a microservices is a popular strategy (“canary testing”). Circuit breakers, working in concert with a staged rollout, protect against these interoperability bugs. By switching a fraction of traffic to the new version, any major problems should show up quickly, and the circuit breaker will prevent them propagating too far within the system.
However, there is still the potential for semantic misconnection. If a service call is made that passes syntactic checks, but has a semantically invalid response—an unexpected empty string, for example—the failure may happen inside the calling code when that is accessed later on.
A Circuit Breaker integrated with RPC will handle this delayed error too, as each interacting service is tracked to completion. The actual transaction flow is validated on each execution. This isolates the interaction between the two instances that have a mutual misunderstanding.
If each end of the call is redundant, but running different version of the code, the coupling that causes the incompatibility will be identified and the call tracing will make it clear which combination is causing the problem by removing that from the flow.
When implemented correctly it is not a service that is isolated, but the particular combination of calling and called services that is failing. This should be flagged in the runtime monitoring.
Netflix's Hystrix example
Netflix’s classic post on circuit breakers making APIs more resilient is an example of this kind of integration error. The initial scenario is an object with fields missing being cached.
One day a bug was discovered where the API was occasionally loading a Java object into the shared cache that wasn’t fully populated, which had the effect of intermittently causing problems on certain devices.
This semantic mismatch is causing failures in multiple different subsystems, so Netflix disable the cache. This ramps up load on the underlying database, causing circuit breakers to throttle DB access, and use a db failure cache instead.
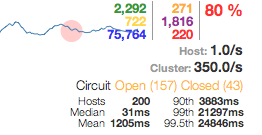
The Hystrix monitoring showed an 80% failure rate, with circuit breakers opening to prevent the database failing further.
What this illustrates is the importance of monitoring the circuit breakers open/closed state, to spot problems before they have cascaded to other parts of the application. Because circuit breakers prevent an outright collapse most of the time, their triggering can go unnoticed.
To return to the network analogy, it’s like using a frayed cable on your network, and seeing the data rate slow down due to retransmissions. If you’re not playing close attention, you may not realise how much packet loss you have from the cable until it starts failing completely.
Velocity needs resilience
On the other side of this, once you have confidence in the ability of circuit breakers to isolate flawed code, this frees you up to experiment more often, and try out new code variants in production with more confidence.
Any large production system will end up with components that have grown to defend against failures in other parts of the system. Using microservices with circuit breakers built into the routing gives a solid base to build on. That means this kind of mitigation can be focused on resilience that matters to users rather than protecting the system from itself.
As well as giving the routing layer more information to work with, circuit breakers can also help make the business logic more resilient. A well-designed Circuit Breaker API enables a series of microservice calls to be treated as a single execution flow, so that it can be monitored and communicated as a whole. This makes it easier to ensure that transactions are atomic, and that they can be treated as such in the monitoring dashboard.
From breaker to broker
If you’re doing Circuit Breakers right, they’re not something that you code into individual microservices, but are part of the infrastructure of your routing between services. They protect the system from both transient failures and buggy code, and are a vital source of information about the health of your microservices ecosystem.